


DATA #011. Breve historia de la analítica web: el pasado (1/3)

Analítica web. Depende del píxel, como casi todo. El píxel o tag es el rey. Envía información de cliente aquí, allá, a su antojo. Si no le da la gana no arranca un nuevo soporte o no se mide una campaña. Es el rey tal y como lo conocemos, sin restricciones, pero por poco tiempo. Como en los mejores westerns, en la barra (antes de COVID-19) está el píxel tomándose un buen scotch (el píxel es un tipo duro, no bebe bourbon), de repente entran Mr. IT, Mr. SEO y Mr. UX.

Dilbert - El dato de los clientes
Mr. IT y Mr. SEO, tipos poco habladores y que valoran la celeridad del servicio, se desesperan al ver al pixel acodado tranquilamente en la barra y compartiendo con el posadero todo tipo de cotilleos sobre los clientes. Realmente no les molesta su indiscreción (no viene de ahora), les molesta el hecho de que (otra vez) van a tener que esperar 10 minutos más para que les sirvan el aguardiente. Ahora también empieza a molestar a Mr. UX que últimamente empieza a estar sensible con los tiempos de respuesta. Todas las siglas de negocio van contra el píxel. Se miran entre ellos y el píxel les devuelve la mirada y se fuma un puro… ¿No se puede matar al píxel? Piensan los tres al unísono.
Tímidamente (el píxel trae consigo un ejército de ventas y hordas de datos, no es alguien a quien se le pueda poner en duda sin un argumento sólido porque habría consecuencias) Mr. IT se acerca a sus dos compinches y les susurra. No es más que un murmullo pero inteligible:
- ¿Y si nos lo cargamos? ¿Y si medimos desde el lado del servidor? La analítica, por ejemplo… tengo un amigo que trabaja en ACME y llevan la analítica con AWStats…
Pero nadie se atreve a desenfundar. El píxel no es un cualquiera, va sobrado. En los últimos años pudo con todos. Con el performance, con la estabilidad web, con la seguridad corporativa, con el data governance, con la privacidad…
De repente, se oyen las puertas giratorias. Alguien ha interrumpido en el centro de la posada. Los tres confabuladores, el píxel y el posadero están mirando fijamente al recién llegado. Solo se oye el sonido de las puertas giratorias. Ñec, ñec, ñec. Es un tipo grande, enorme, una silueta gigante a contraluz. Dispara y hay scotch por todo. El píxel ha muerto, el data privacy es el rey.
Mr. Data privacy se acerca a la barra:
- “Pedíos algo. Muerto el perro, se acabó la rabia. La analítica web será server-side, la única solución viable a largo plazo.”
El tracking de los clientes server-side se presenta como la única solución definitivamente sostenible en los próximos años ya que cubre todas las advertencias y restricciones presentes y futuras del tracking client-side.
En esta serie de tres artículos acerca del desarrollo y la evolución de la analítica web veremos una breve historia de cómo hemos llegado a la analítica client-side o basada en lanzamiento de píxeles a servidores externos con datos de clientes y una aproximación razonada a por qué el tracking de los clientes server-side se presenta como la única solución definitivamente sostenible en los próximos años ya que cubre todas las advertencias y restricciones presentes y futuras del tracking client-side.
1 - El origen de la analítica web: los logs de servidor
La analítica web se originó a través de los análisis de los logs de servidor a principios de la década de los 90. Las estadísticas de un sitio web consistían principalmente en contar el número de solicitudes (o visitas) realizadas al servidor. Los servidores web registran las solicitudes (no todas, luego veremos por qué) que se les realizan en un registro denominado log. Pronto se cayó en la cuenta que mediante un programa se podía leer estos archivos de registro para proporcionar datos sobre la intensidad de tráfico que recibía (y que respondía) el sitio web. Por tanto, estos programas sólo procesan la información del lado del servidor. Cada solicitud al servidor, sin importar cuál sea y quién la realice, se registra en los logs del servidor.
Los 3 grandes problemas
Y entonces, debido a la complejidad de Internet, y a los bots debido a la indexación de los motores de búsqueda y agregadores de contenido (aunque estos normalmente a través de feeds) y, por qué no decirlo, también debido a los spammers, hackers y scrapers surgieron a la luz importantes deficiencias si se realiza la analítica en base a los datos registrados en los logs de los servidores. Hay 3 problemas fundamentales.

La inmensa cantidad de bots han obligado a las webs a recurrir a diferentes tipos de validaciones.
Los tres grandes inconvenientes:
Distinguir usuarios reales de bots: el principal problema es que no todas las solicitudes de las páginas web son de personas reales. Según Sharvil Shetty sólo el 63% del tráfico es realmente iniciado por humanos. A través de la monitorización y análisis de los logs del servidor, es difícil filtrar robots, crawlers, spiders y otras visitas que no corresponden a usuarios cuando estos bots no vienen auto-identificados. Y hay mucho tráfico de bots automatizados en Internet. Sí, muchos.
Pérdida de hits: por respuesta desde cachés y proxys tal y como está construida la arquitectura de Internet.
Pérdida de usuarios únicos: debido a la unificación de solicitudes desde routers/firewalls.

Sharvil Shetty - Sólo el 63% del tráfico es iniciado por humanos
En cuanto al problema (2) y (3)... ¿cómo de grande es la brecha de datos comparado con, por ejemplo, si capturásemos los datos para realizar la analítica desde el lado del cliente? Es decir, vía píxel (JavaScript) tal y como hacemos con Google Analytics.
¿Cómo de grande es la brecha de datos entre el análisis a través de logs de servidor y vía píxel?
Para entender las diferencias, la brecha en los datos obtenidos entre estos dos enfoques es imprescindible entender la arquitectura clásica simplificada de cliente-servidor en una solicitud a través de Internet (habrá muchas variaciones):

Analítica web a través de los logs del servidor
En este proceso hay 3 pasos claramente diferenciados:
Paso 1 (azul). El cliente solicita la página web al navegador. Éste consulta su caché y:
Si no la tiene almacenada la solicita a “Internet”, es decir al router/firewall que opera como puerta a Internet (aunque no está en el esquema pueden darse casos de firewalls con caché). Si la solicitud se hace desde dos ordenadores distintos, el servidor web sólo verá dos solicitudes distintas desde el mismo nodo. Se diluye el concepto de usuario único (con líneas rojas discontínuas y una A roja en el gráfico).
Si el navegador tiene la web almacenada en su caché, la sirve desde la caché y… punto importante: el servidor no se enteraría nunca de esta petición (con líneas rojas discontínuas y una B roja en el gráfico).
Paso 2 (rojo). Si el navegador no tenía la página web en caché (punto 1.1.) la solicita a Internet vía router/firewall que hace la petición a “Internet” ¿A quién? Simplificando digamos que al ISP (el proveedor de servicio de Internet) quién reenvía la solicitud al ISP que utiliza la empresa del servidor web. Y entre estos dos puntos está todo el berenjenal de servidores proxy y proxys cachés. Dónde lo único importante ahora es saber que si alguno de estos proxys encuentra la página web solicitada en su caché o no la encuentra. En este último caso, la solicita al servidor web. En resumen:
Si ninguno de los proxys que conforman el entramado la tiene en caché, acabarían solicitándola al servidor web.
Si algún proxy intermedio la tiene disponible y está actualizada, la sirve desde la caché y… punto importante: el servidor no se enteraría nunca de esta petición (con líneas rojas discontínuas y una B roja en el gráfico).
Paso 3 (en amarillo). Cuando el servidor web recibe la petición desde Internet, revisa su caché para ver si dispone de ella en caché:
Si no la tiene, procesa la lógica del código y devuelve el documento HTML. Si no hay CDNs de por medio devolvería el HTML y además los archivos js, css, imágenes, vídeos que sean necesarios.
Si la tiene, responde desde la caché. Aquí depende de la implementación de cada servidor web puede ser que se registre en el log o puede ser que no. En este último caso, el servidor no se enteraría de esta petición (con líneas rojas discontínuas y una B roja en el gráfico).
Ventajas e inconvenientes de la analítica a través de logs de servidor
Sin embargo este procesado de logs del servidor tiene varias ventajas frente a la analítica web client-side a través de píxel:
No tiene impacto en la performance de la página web: velocidad y tiempo de carga.
No está bloqueada por navegadores implicados con la privacidad, extensiones de bloqueo de anuncios y otros bloqueadores de contenido.
Contabiliza incluso aquellos visitantes que deshabilitan JavaScript en sus navegadores.
Es fácil detectar tráfico de determinadas redes o subredes para no tenerlo en cuenta, esto es especialmente útil para no contabilizar sesiones de empleados de la compañía, proveedores o agencias que realizan pruebas (aquí un artículo de Johanna Álvarez de como realizar esto en una implementación client-side).
No se necesitan integraciones de terceros.
Pero las desventajas de utilizar logs del servidor lo han dejado relegado a un uso minoritario en lo que a analítica web se refiere:
Los logs del servidor no molan, no son fáciles de usar y la experiencia del usuario no es la que te gustaría. Las herramientas no suelen ser fáciles de configurar y la interfaz de usuario tampoco es fácil de usar y comprender. Vamos, todo facilidades.
Los análisis realizados en base a los datos del log del servidor no son precisas en comparación con las estadísticas que puedes ver en herramientas como Google Analytics. Una cantidad brutal del tráfico vienes de motores de búsqueda, crawlers y bots. Cómo encontrar los datos válidos referentes a las navegaciones de usuarios reales en medio del ruido y cómo filtrar los bots son tareas que requieren conocimiento y tiempo.
Los logs del servidor no son infinitos. Si se desea almacenar un histórico es necesaria una solución donde ir volcando los datos periódicamente.
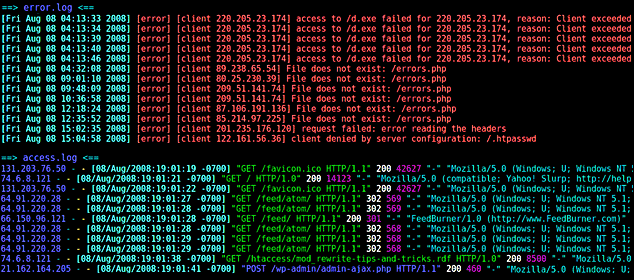
Analítica web a través de los logs de servidor. Ejemplo de logs (error.log y access.log).
Conclusión
Y con todas estas desventajas llegó Google Analytics a nuestras vidas y todos cedimos encantados los datos de nuestros usuarios y clientes a Google. La precisión de los datos, la calidad de la presentación de la información y el plug-&-play de Google se impuso y a día de hoy no es una solución factible y realista el análisis a través de los logs de servidor.
Y con la facilidad de ingestar/explotar la información a/desde un sistema externo llegó el píxel o tag como pieza indispensable para conseguir esto. Él es el man-in-the-middle en un entorno "marketiniano" dónde todo es para ayer y con un trocito de código JS embebido en nuestra página web podemos alimentar los más refinados algoritmos de empresas externas. Un trocito de código indispensable que tu proveedor te facilita y que te guía para implementar en un periquete. Fácil, limpio. Y el proveedor ya está recibiendo los datos necesarios para poner en marcha sus servicios. Así se convertiría el píxel en el rey indiscutible de la capa más estratégica de los datos, la de la interoperabilidad.
Breve historia de la analítica web - Píxel de Facebook
En la próxima entrega indagaremos en las ventajas que trajo la analítica client-side con Google Analytics como producto líder del mercado. La analítica que tiene al píxel como principal protagonista de la recogida de datos hacía un servidor externo donde se consolida la recolecta y el procesado de los datos. Profundizaremos en cómo funciona, en qué radica su éxito y por qué es un modelo que va a quedar obsoleto debido a los fuertes inconvenientes y restricciones que se están imponiendo.

Breve historia de la analítica web. De los logs del servidor al píxel